As you may know, a text file may specify its encoding by a ‘bom’ (byte order mark) using several bytes at its beginning. For utf8 encoding the signature bytes are: 0xef, 0xbb, 0xbf.
I came across an issue while manipulating csv files, for which I decided to use utf8 (thinking that was a good choice for a multi-cultural environment!). The process involved reading and writing back to the same file after some insertions and updates. All using microsoft.jet.oledb.4.0 provider (with a schema.ini specifying CharacterSet=65001 (65001 being utf8 code page)).
My csv files had a header row of which the first column was, ironically, named ‘Match ID’. A few manipulations revealed a somehow strange behavior. Although the debugger showed that the first column’s name is ‘Match ID’, I could no more access ‘Match ID’ column by its name. Using the watch window, I asked the debugger:
myColumn.ColumnName == "Match ID"… it replied false… weird!
Viewing the column name's CharArray in hexa offers a more significant information:
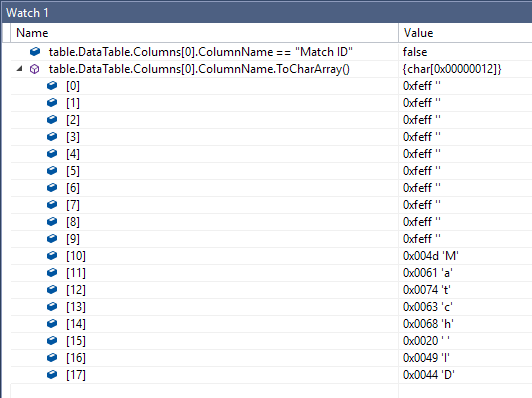
That is evidently endless! With the time going, as you manipulate your columns and rewrite back to the csv file, you end up by having your 'Match ID' column prefixed by bytes from the utf8 bom code as many times you rewrite the csv file. And if you are a nice guy who lets the users reorder the columns as they need, you may end up by having all your columns affected by that issue!

Changing files’ encoding to unicode (whose bom signature is 0xff 0xfe 0xff 0xfe) does not reproduce the issue. Which makes it clear that the source of annoyance is not utf8 but rather the jet.oledb.4 data provider with utf8. Still, identifying the source is half way of solving the issue :).
How to solve this?
Well, you may think of ‘sanitizing’ your column names at every load! Which, in my view, does not seem quite practical.
In my case I just switched to unicode (despite more bytes waste!) to preserve multi-cultural data requirements.