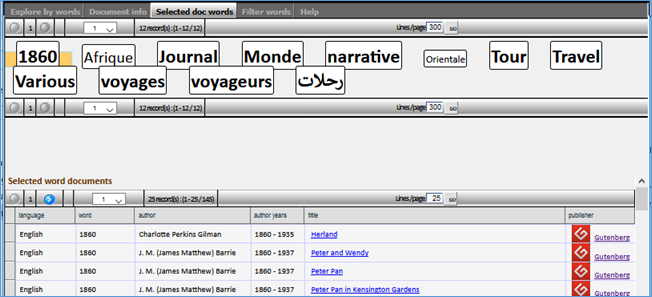
Objectives:
- Display a cloud of index words, each dimensioned relative to its occurrences in e-book information (e-book title, description, author, editor… etc.)
- On selection of a given word: display the list of e-book references related to the selected word
- On selection of an e-book: display its information details and all words linked to it
Context:
doc5ync web interface is based on a meta-model engine (simpleSite, currently being renamed to web5ync!).
I talked about meta-models in a past post Here, with some posts about its potential applications here.
The basic concept of meta-models is to describe an object by its set of properties and enable the user to act on these properties by modifying their values in the meta-model database. On runtime, those property values are assigned to each defined object.
In our case, for instance, we have a meta-model describing web page elements, and a meta-model describing the dataset of word index and their related e-books.
For web page elements, the approach considers a web page as a set of html tags (i.e. <div>, <table><tr><td>…, <img… etc.). Where each tag has a set of properties (style, and other attributes) for which you can define the desired values. On runtime, your meta-model-defined web page comes to life by loading its html tags, assigning to each the defined values and injecting the output of the process to the web response.
A dataset is similarly considered as a set of rows (obtained through a data source), each composed of data cells containing values. Data cells can then be either presented and manipulated through web elements (html tags, above) or otherwise manipulated through web services.
Data storage and relationships
As we mentioned in the previous post, index words and their related e-books are stored in database tables as illustrated in the following figure:
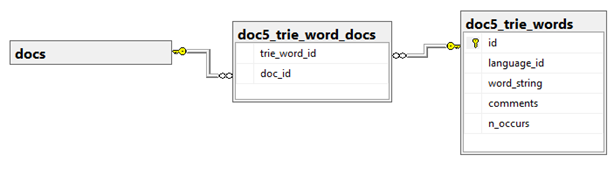
Each word of the index provides us with its number of occurrences in e-book text sequences (known on Trie scan).
Html formatting using a SQL view
To reflect this information into a presentation, we used a view to format a html div element for each word relative to its number of occurrences. The query looks like the following code
select
w.id as word_id
, w.n_occurs
, N'<div style="BASIC STYLE STRING HERE…; display:inline;'
-- add the font-size style relative to number of occurrences
+
case
when w.n_occurs between 0 and 2 then N' font-size:10pt;'
when w.n_occurs between 3 and 8 then N' font-size:14pt;'
when w.n_occurs between 9 and 15 then N' font-size:16pt;'
when w.n_occurs between 16 and 24 then N' font-size:22pt;'
when w.n_occurs between 25 and 2147483647 then N' font-size:26pt; '
end
+ N'"'
-- add whatever html attributes we need (hover/click…)
+
N' id="div' + convert(nvarchar(32), w.id)
+ N'" onclick="select_data_cell(''' + convert(nvarchar(32), w.id) + N''');" '
as word_string_html
-- add other columns if needed
from dbo.doc5_trie_words w
order by w.word_string
|
The above view code provides us with html-preformatted string for each word index in the data row.
Tweaking the data rows into a cloud of words
On a web page, a dataset is commonly displayed as a grid (table / columns / rows), and web5ync knows how to read a data source, and output its rows into that form. But that did not seem to be convenient in our case, because it simply displays index words each on a row which is not really the presentation we are looking for!
To resolve this, we simply need to change the dataset web container from a <table> (and its containing rows / cells) into <div> tags (with style=display: inline).
Here a sample of html code of the above presentation:
<table>
<tr>
<td>
<div style="font-size:16pt;" onclick="select_data_cell('29008');">After</div>
</td>
</tr>
<tr>
<td>
<div style="font-size:26pt; onclick="select_data_cell('28526');">after</div>
</td>
</tr>
<!-- the table rows go on... -->
|
And here is a sample html code of the presentation we are looking for:
<div style="display:inline;">
<div id="td_word_string_html82" style="display:inline;">
<div style="font-size:26pt;" onclick="select_data_cell('28526');">after</div>
</div>
</div>
<div style="display:inline;">
<div id="td_word_string_html83">
<div style="font-size:16pt;" onclick="select_data_cell('29008');">After</div>
</div>
</div>
<div style="display:inline;">
<div style="display:inline;">
<div style="font-size:10pt;" onclick="select_data_cell('17657');">AFTER</div>
</div>
</div>
|
Which looks closer to what we want:

Interacting with index words
The second part of our task is to allow the user to interact with the index words: clicking a word = display its related e-books, clicking an e-book = display the e-book details + display index words specifically linked to that e-book.
For this, we are going to use a few of the convenient features of web5ync, namely: Master/details data binding, and Tabs. (I will write more about these features in a future post)
Web5ync master/details binding allows linking a subset of data to a selected item in the master section. Basically, each data section is an iframe. The event of selecting a data row in one iframe can update the document source of one or more iframes. All what we need is: 1. define a column that will be used as the row's id, and 2. define how the value of that id should be passed to the target iframe (typically: url parameter name).
Tabs are convenient in our case as they will allow distributing the information in several areas while optimizing web page space usage.
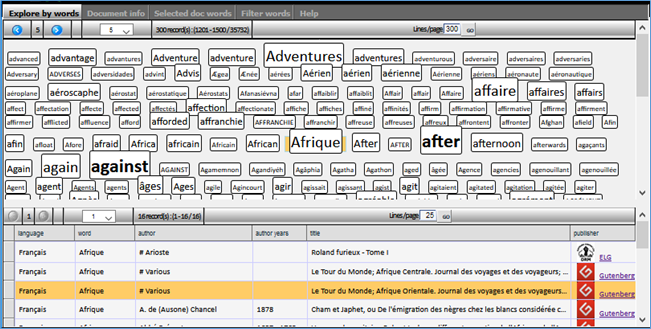
In the figure above, we have 3 main data tabs: n Explore by words, n Document info and n Selected document words.
On the first tab:
- clicking a word (in the upper iframe) should display the list of its related e-books (in lower iframe of that same tab)
- clicking an e-book row on the lower iframe should: first displays its details (an iframe on the second tab), and display all words directly linked to the selected e-book (an iframe in the 3rd tab). (figures below)
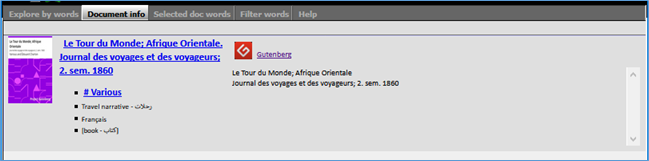

In that last tab, we can play once again with the displayed words, to show other documents sharing one of them: