DeepZoom has been one of the most inspiring projects/technologies in last years. Its approach is now extensively used in various domains, notably in mapping applications.
I think DeepZoom approach still have more application areas to explore.
In this article, I will explore one question where the DeepZoom approach can be quite useful.
KML Polygons
KML (Keyhole Markup Language) is an XML-notation-based 'language' now widely used to describe geographic data. Among many types of data, KML includes Polygons, which describe point locations on a map. A polygon may, for instance describe the contour of political frontiers of a country or a seashore…, which may thus contain a large number of point-coordinates.
As each of the polygon's points may be associated with more or less large data objects, processing the polygon information may become a challenging operation either on a server or on a client machine. Reducing manipulated polygon data size and required processing efforts is thus an important performance question.
One of the techniques often used is to compress (zip) the KML transmitted files' data (to produce .kmz files instead of .kml). But there should be a better approach in simply transferring (or processing) only significant point's data.
Zoom level and view port
When we view or display a map, we in fact view in a zoom level. According to this zoom level, two points may have a significant distance or be confused into one same point.
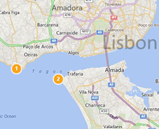
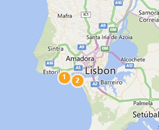
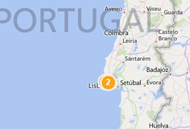
The following figures illustrate this:
- At the first zoom level, point 1 and point 2 are clearly distinct
- The more we zoom-out, the less distinctive they become
- Until both can be considered as one same point
Conclusion: according to the zoom-level, we may transfer (or manipulate/process) only one of those points instead of both.
|
|
|
|
|
Zoom level1
|
Zoom-out1
|
Zoom-out2
|
This can also be illustrated by the DeepZoom 'pyramid' approach:
A map is also viewed into a 'View Port' (the window through which we view the map).
For the two points of the previous example, at certain zoom-in level (or view port coordinates change), one (or both) of them may be located out of the view port.
Another conclusion: we don't need to transfer (or manipulate/process) polygon points which may be located outside of the current view port.
The delivered code sample
The downloadable code includes the data of a polygon composed of a large array of points.
The sample uses several parameters to determine which points to be considered for transfer or processing:
- The view port coordinates: used to select only points inside the view port
- The zoom level: associated with a ratio used to compare the significance of points' coordinates variations
The ZoomPortView object exposes few properties: a Name, a ZoomRatio, TopLeft and BottomRight points (Width and Height are calculated according to those points' coordinates).
The ZoomPolygon object exposes few properties: a list of polygon's Points. For the sake of current demonstration, the object also exposes PointsOutOfPortView which is a list of points that are out of the current port view.
ZoomPolygon class offers a static method which parses an array of points according to a given port view, returning the related new ZoomPolygon object.
public static ZoomPolygon Parse(Point[] points, ZoomPortView portView)
{
ZoomPolygon polygon = new ZoomPolygon(portView);
ObservableCollection<Point> pointList = new ObservableCollection<Point>();
ObservableCollection<Point> pointsOutPortView = new ObservableCollection<Point>();
double zoomRatio = portView.ZoomRatio;
double maxX = portView.Width,
maxY = portView.Height;
Point point,
last = new Point();
for(int index = 0; index< points.Length; index++)
{
point = points[index];
if( ! portView.IsPointInPortview(point))
{
pointsOutPortView.Add(point);
goto next_point;
}
if (pointList.Count <= 0)
{
pointList.Add(point);
goto next_point;
}
if( Math.Abs( (point.X - last.X) / maxX) >= zoomRatio
|| Math.Abs( (point.Y - last.Y) / maxY) >= zoomRatio)
pointList.Add(point);
next_point:
last = point;
}
polygon.Points = pointList;
polygon.PointsOutOfPortView = pointsOutPortView;
return polygon;
}
Note: the code above can of course be more compact using Linq. This version seems more illustrative of the logic to include / exclude polygon points.
Sample screen shots
Download the sample code
KmlOptimizerSample.zip (1.28 mb)
Acknowledgement
Thanks to all my friends at Thomson Reuters' iMap Project with whom I learnt much about kml and maps in general: Benoît, Florent, Catalin, Christophe, Ronan, John, Geffe, Calum…