[json objects =>to property bags =>to objects]
Reducing dependency between clients and services is a major common question in software solutions.
One important area of client/server dependencies lies in the structure of objects involved in exchanged messages (requests / responses). For instance: a new property inserted to an object on service side, often crashes the other side (client) until the new property is introduced on the involved object.
I previously posted about loose coupling through property bags abstractions.
My first approach was based on creating a common convention between service and client which implies transforming involved objects into property bags whose values would be assigned as needed to business objects at each side on runtime. That still seems to be a 'best solution' in my point of view.
Another approach is to transform the received objects (at either side: server/client) into property bags before assigning their values to the related objects.
This second approach is better suited for situations where creating a common convention would be difficult to put in place.
While working on some projects based on soap-xml messages, I wrote a simple transformer: [xml => property bags => objects].The transformer then helped write an xml explorer (which actually views xml content as its property bag tree. You can read about this in a previous post).
Another project presented a new challenge in that area, as the service (JEE) was using Json format for its messages. In collaboration with the Java colleagues, we could implement the property bag approach which helped ease client / server versioning issues.
A visual tool, similar to xml explorer, was needed for developers to explore json messages' structures. And that was time for me to write a new json <==>-property bag parser.
The goal was to:
- Transform json content to property bags
- Display the transformed property bag tree
Using Newtonsoft's Json library – notably its Linq extensions – was essential.
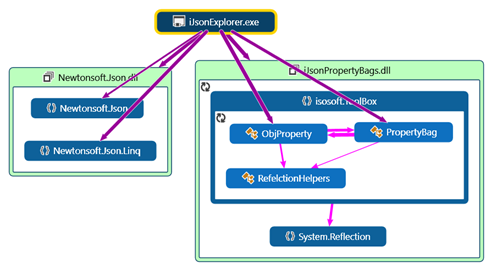
Hereafter the global dependency diagram of the Json explorer app:
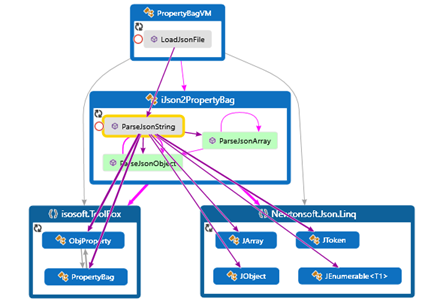
The main method in the transformation is ParseJsonString to which you provide the string to be parsed.
Its logic is rather simple:
Code snippets
The parse json string method
public static PropertyBag ParseJsonString(string jsonString)
{
JObject jObj = null;
PropertyBag bag = new PropertyBag("Json");
ObjProperty bagRootNode;
JArray jArray = null;
string exceptionString = "";
/// the json string is either:
/// * a json object
/// * a json array
/// * or an invalid string
// try to parse the string as a JsonObject
try
{
jObj = JObject.Parse(jsonString);
}
catch (Exception ex)
{
jObj = null;
exceptionString = ex.Message;
}
// try to parse the string as a JArray
if(jObj == null)
{
try
{
jArray = JArray.Parse(jsonString);
}
catch (Exception ex2)
{
jArray = null;
exceptionString = ex2.Message;
}
if(jArray == null)
{
bag.Add(new ObjProperty(_exceptionString, null, false) { ValueAsString = exceptionString });
return bag;
}
}
bagRootNode = new ObjProperty("JsonRoot", null, false);
if(bagRootNode.Children == null)
bagRootNode.Children = new PropertyBag();
bag.Add(bagRootNode);
if(jObj != null)
{
bagRootNode.SourceDataType = typeof(JObject);
bagRootNode.Children = ParseJsonObject(bagRootNode, jObj);
}
else if(jArray != null)
{
bagRootNode.SourceDataType = typeof(JArray);
bagRootNode.Children = ParseJsonArray(bagRootNode, jArray);
}
return bag;
}
Parse json array code snippet
private static PropertyBag ParseJsonArray(ObjProperty parentItem, JArray jArray)
{
if(parentItem == null || jArray == null)
return null;
ObjProperty childItem;
if(parentItem.Children == null)
parentItem.Children = new PropertyBag();
PropertyBag curBag = parentItem.Children;
foreach(var item in jArray.Children())
{
JObject jo = item as JObject;
JArray subArray = item as JArray;
PropertyBag childBag;
Type nodeType = subArray != null ? typeof(JArray) : typeof(JObject);
childItem = new ObjProperty("item", parentItem, false) { SourceDataType = nodeType };
if (jo != null)
childBag = ParseJsonObject(childItem, jo);
else if(subArray != null)
childBag = ParseJsonArray(childItem, subArray);
else
continue;
curBag.Add(childItem);
}
return curBag;
}
Json to Xml
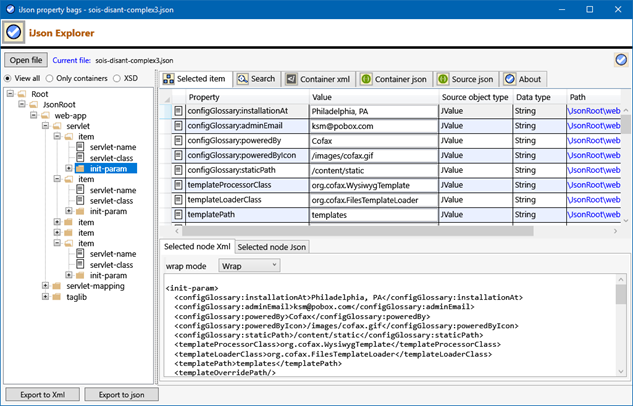
As, now, we have the json content in property bags, we can almost directly get the xml equivalent (see screenshot below).
The used sample json string: for the following screenshot:
{
"web-app": {
"servlet": [
{
"servlet-name": "cofaxCDS",
"servlet-class": "org.cofax.cds.CDSServlet",
"init-param": {
"configGlossary:installationAt": "Philadelphia, PA",
"configGlossary:adminEmail": "ksm@pobox.com",
"configGlossary:poweredBy": "Cofax",
…
…
"maxUrlLength": 500
}
},
{
"servlet-name": "cofaxEmail",
"servlet-class": "org.cofax.cds.EmailServlet",
"init-param": {
"mailHost": "mail1",
"mailHostOverride": "mail2"
}
},
{
"servlet-name": "cofaxAdmin",
"servlet-class": "org.cofax.cds.AdminServlet"
},
{
"servlet-name": "fileServlet",
"servlet-class": "org.cofax.cds.FileServlet"
},
{
"servlet-name": "cofaxTools",
"servlet-class": "org.cofax.cms.CofaxToolsServlet",
"init-param": {
"templatePath": "toolstemplates/",
"log": 1,
…
…
"adminGroupID": 4,
"betaServer": true
}
}
],
"servlet-mapping": {
"cofaxCDS": "/",
"cofaxEmail": "/cofaxutil/aemail/*",
"cofaxAdmin": "/admin/*",
"fileServlet": "/static/*",
"cofaxTools": "/tools/*"
},
"taglib": {
"taglib-uri": "cofax.tld",
"taglib-location": "/WEB-INF/tlds/cofax.tld"
}
}
}
Screenshot
You may download the binaries here!
The source code is available here!