You probably know about Swagger?
Swagger:
|
OpenAPI Specification (originally known as the Swagger specification) is a specification for machine-readable interface files for describing, producing, consuming, and visualizing RESTful web services.
|
In a way, Swagger does what soap does for wsdl generated files.
It produces a .json file containing the given service information (data types, operations, parameters… etc.).
I came to know Swagger some days ago on a client site and that was quite useful to document defined services. The UI provided to access those information was quite poor though.
I looked for a more convenient UI for reading the provided .json, but could not find something available. I thus decided to write my own…. Which is the subject of this post.
I first thought it would be quite straightforward: just define objects that match the json structure / parse the json code into my objects… et voilà. I admit I was too optimistic!
The swagger.json schema
Let us first try to understand the structures defined in the generated .json file. I read many articles (some rather obscure!) about that, but through the work craft my understanding got betterJ. Here are the conclusions seen through a .net developer view:
Swagger json file is composed of:
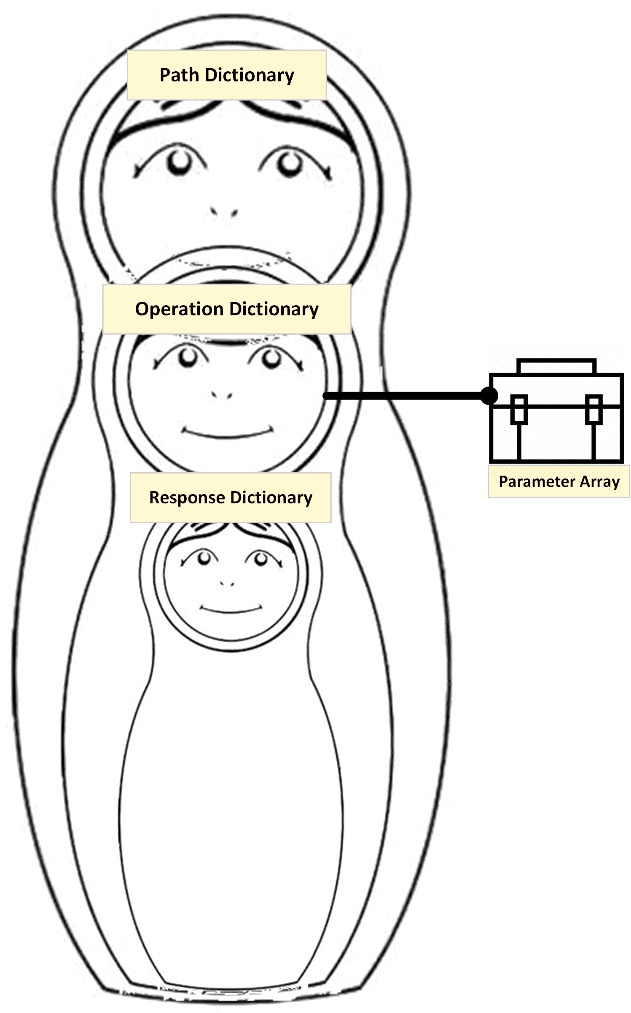
A global (root) service definition, itself composed of (most significant elements for clarity)
- A Dictionary of service paths:
- Key = path url
- Value = Dictionary of operations available at that address. Itself composed of:
- Key = operation name
- Value = the operation object. Composed of:
- General info (name, description, summary… etc.)
- Operation’s Verb (example: get, post, set, put…)
- An array of Parameter objects:
- Description
- (In) = Where should it be located (example: in the request’s path, argument or body…)
- Is required (bool flag)
- Parameter’s data type
- Operation Responses object = Dictionary of:
- Key = response code (example: 200, default…)
- Value = response object:
- Description
- Response data type
Remark: you may notice that operation parameters are defined as an array. I think they would better be defined as a dictionary as parameter names should be unique within the same operation.
After the paths node, the schema continues with another interesting node:
- A Dictionary of service’s data types:
- Key = data type name
- Value = Dictionary of data type members:
- Key = element name
- Value = a data type object:
- Type (example: object, string, array… may refer to a defined data type object)
- Element data type (for objects of type array). Refers to a defined data type.
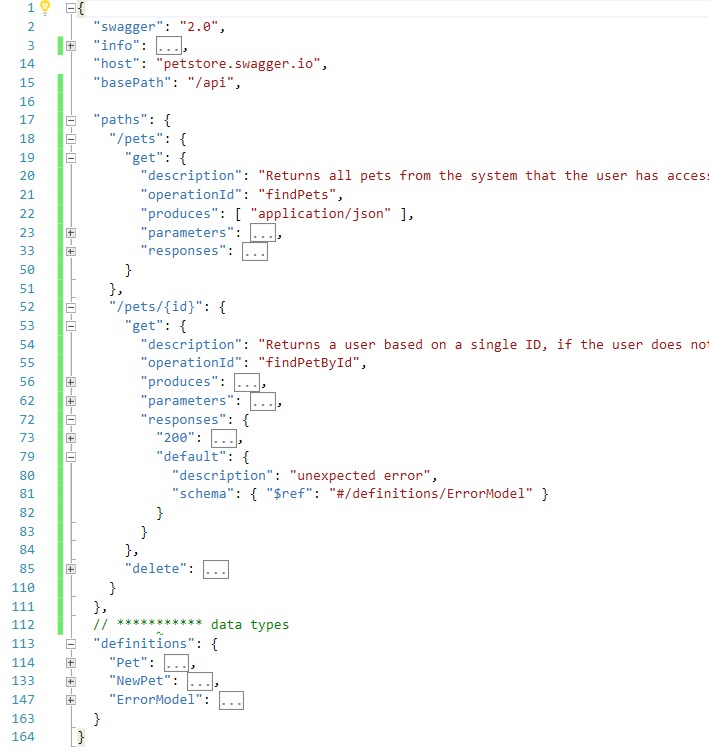
Here is a screen capture of significant nodes in a sample swagger json file. You may find more samples here.
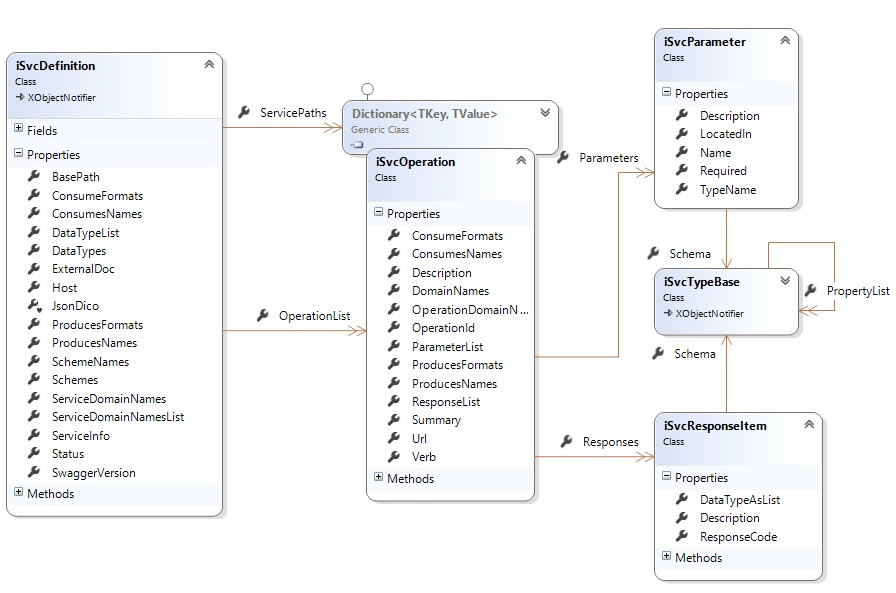
The objects of the schema can be presented in the following class diagram (note that the ServicePaths dictionary Value is a Dictionary of string, iSvcOperation… I could not find a way to represent this relation in the diagram):
To parse the swagger json data, we will use the now famous NewtonSoft.Json library.
That needs us to add some attributes for the parse process to go right.
Example, in our root class iSvcDefinition:
The service domain names array should parsed, so we tell the library about its model name:
[JsonProperty("tags")]
public iSvcDomain[] ServiceDomainNames { get; set; }
The class contains a property that should not be parsed… so, we tell the parser to ignore it:
[JsonIgnore]
public List<iSvcDomain> ServiceDomainNamesList
{
get { return ServiceDomainNames == null ? null : ServiceDomainNames.ToList(); }
}
So far, so good… we have objects that correctly represent the swagger json model (complemented by some view model properties in this example!).
We still have a problem: resolving data type references!
Resolving json references
Data types of elements in our swagger json file are specified as references to the related data-type-definition. For example, a Response that returns a ‘Product’ object is serialized as:
"responses": {
"200": {
"description": "An array of products",
"schema": { "type": "array",
"items": { "$ref": "#/definitions/Product" }
}
},
The full definition of the ‘Product’ data type is defined elsewhere, as:
"Product": {
"properties": {
"product_id": {
"type": "string",
"description": "Unique identifier of the product."
},
"description": {
"type": "string",
"description": "Description of product."
},
"display_name": {
"type": "string",
"description": "Display name of product."
},
"image": {
"type": "string",
"description": "Image URL representing the product."
}
}
}
So each item of ‘Product’ data type will tell the reference of that type (instead of duplicating definitions).
Resolving json references while parsing needs some craftingJ
In fact, the json parser does not resolve references automatically. That is part 1 of the problem. Part 2 is the fact that to find a referenced item, it should exists. That is: it should have already been parsed. Which requires the data type definitions to be at the beginning of the parsed file. A requirement that is, at least, not realistic.
As always, I searched the web for a sustainable solution. You will find many about this question, including “how to Ignore $ref”… which is the exactly the opposite of what we are looking for in this contextJ
The solution I finally used is:
- Use the JObject (namespace Newtonsoft.Json.Linq) to navigate as need through the swagger json nodes
- Start the parse process by:
- Deserializing the swagger "definitions" node which contains the data types definitions
- Store data types into a Dictionary: key = type id (its path), Value = the data type object
- Use a custom resolver (a class which implements the IReferenceResolver (namespace Newtonsoft.Json.Serialization) to assign the related data type object each time its reference is encountered.
Here is the essential code-snippets for resolving references:
// define a dictionary of json JToken for data types
internal static IDictionary<string, JToken> JsonDico { get; set; }
// a dictionary of data types
IDictionary<string, iSvcTypeBase> _types = new Dictionary<string, iSvcTypeBase>();
// create a JObject of the file’s json string
JObject jo = JObject.Parse(jsonString);
// navigate to the definitions node
Var typesRoot = jo.Properties().Where( i => i.Name == "definitions").FirstOrDefault();
// store dictionary of type_path / type_token
if (typesRoot != null)
JsonDico = typesRoot.Values().ToDictionary( i => { return i.Path; });
Now, we can build our data-type-dictionary using the JTokens:
foreach(var item in JsonDico)
{
// deserialze the data type of the JToken
iSvcTypeBase svcType = JsonConvert.DeserializeObject<iSvcTypeBase>(item.Value.First.ToString());
// add the data type to our dictionary (reformat the the item’s key)
_types.Add(new KeyValuePair<string, iSvcTypeBase>("#/" + item.Key.Replace(".", "/"), svcType));
}
Our resolver can now return the referenced item to the parser when needed:
public object ResolveReference(object context, string reference)
{
string id = reference;
iSvcTypeBase item;
_types.TryGetValue(id, out item);
return item;
}
Some screen captures:
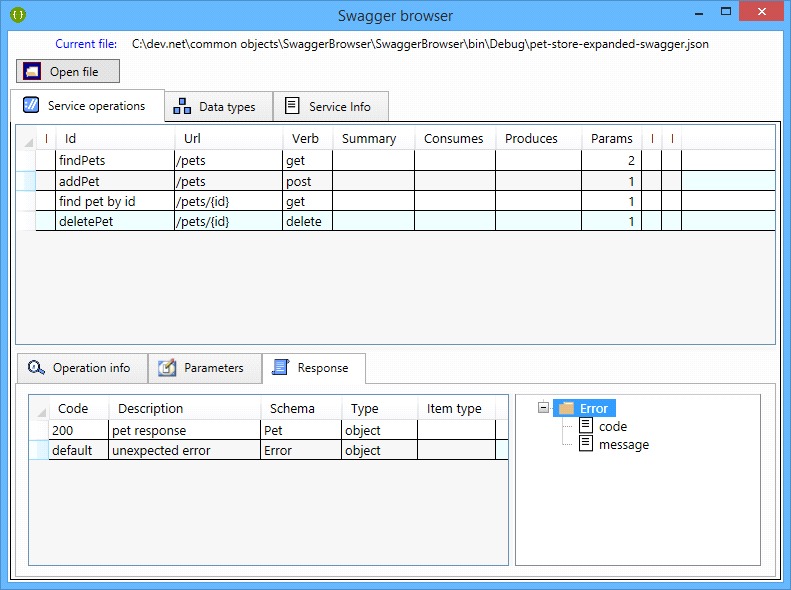
You may download the binaries here.
Will post the code later (some cleanup requiredJ)