SQL recursive schemas
One of the interesting features of relational databases is the possibility for a table to reference itself.
Suppose we want to represent the file folder system in a database. We can define a table having, for example, 3 fields: id, parent_id and name:
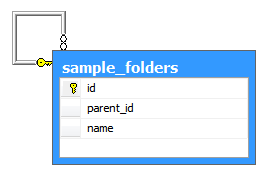
We can then create a self referencing relationship between the id and parent_id field.
Simple (and elegant) solution!
Yes, but that also let us inherit all specific constraints of recursive patterns.
The figure above shows the simple (and somehow elegant) of the table schema or pattern.
What it doesn’t show is how the ‘real world’ records will look like when stored in the table:
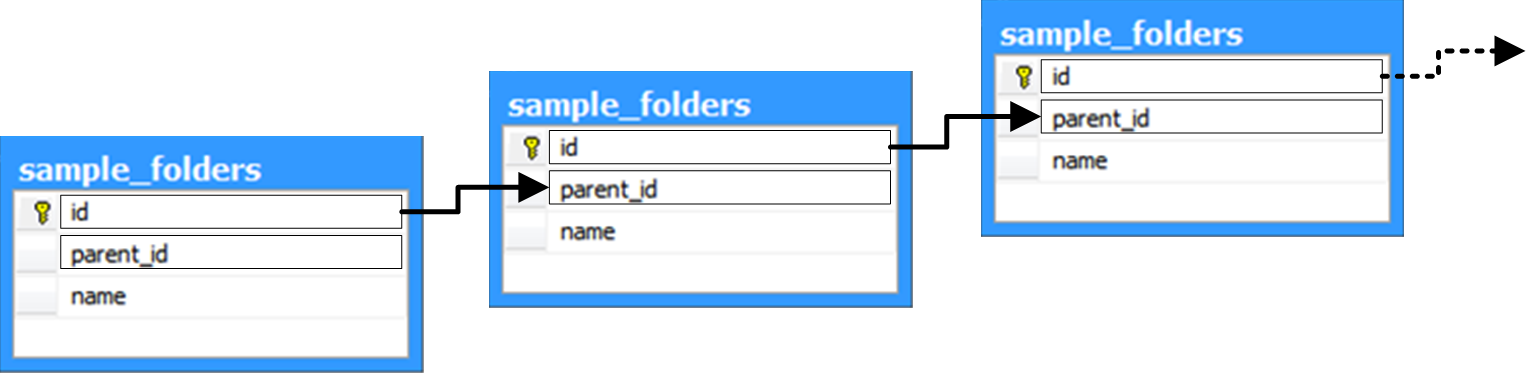
Two important constraints of such recursive schema are:
· Path readability: i.e. as the schema allows an infinite nest levels, reading an item path may cause a stack overflow;
· Cyclic references: i.e. a folder that references itself (or one of its children) as a parent (which may end up by creating infinite path readability loop;
The Nest level problem
A function or stored procedure for reading an item path may look like this:
CREATE FUNCTION dbo.Read_path
(
@item_id int
)
RETURNS nvarchar(max)
AS
BEGIN
declare @parent_id int,
@path nvarchar(max),
@name nvarchar(50)
select @parent_id = parent_id,
@name = name
from dbo.sample_folders
where(id = @item_id)
if @parent_id is null
return @name
-- recursive call
return dbo.Read_path ( @parent_id) + N'\' + @name
END
GO
Such a function will work nicely as long as the folder’s nest level remains in a ‘reasonable’ value. For example, in MS SQL Server, nest level (recursive call stack whose value can be returned at any time by the @@nestlevel system function) has a maximum of 32.
So, it is more precautious to test current @@nestlevel value before proceeding:
if @@nestlevel >= 32
return N'Path nest level exceeds allowed value'
However, doing so breaks the efficiency and usability of our pattern. The best solution would be to get rid of the recursive call inside our function. Here is an example using a goto label:
DECLARE @folder_name nvarchar(255),
@parent_id int,
@cur_item_id int,
@path nvarchar(max)
SELECT @path = N'',
@cur_item_id = @item_id
-- recursion label
get_nested_path:
SELECT @folder_name = f.name,
@parent_id = f.parent_id
FROM dbo.sample_folders AS f
WHERE( f.id = @cur_item_id)
if @parent_id is null
begin
-- We are on the root
return @folder_name + @path
end
select @cur_item_id = @parent_id,
@path = N’\’ + @folder_name + @path
-- goto recursion label
goto get_nested_path
Cyclic references problem
Our read path function can still be trapped into an infinite loop that can be caused by cyclic references… i.e. a folder referencing itself or one of its children as a parent:
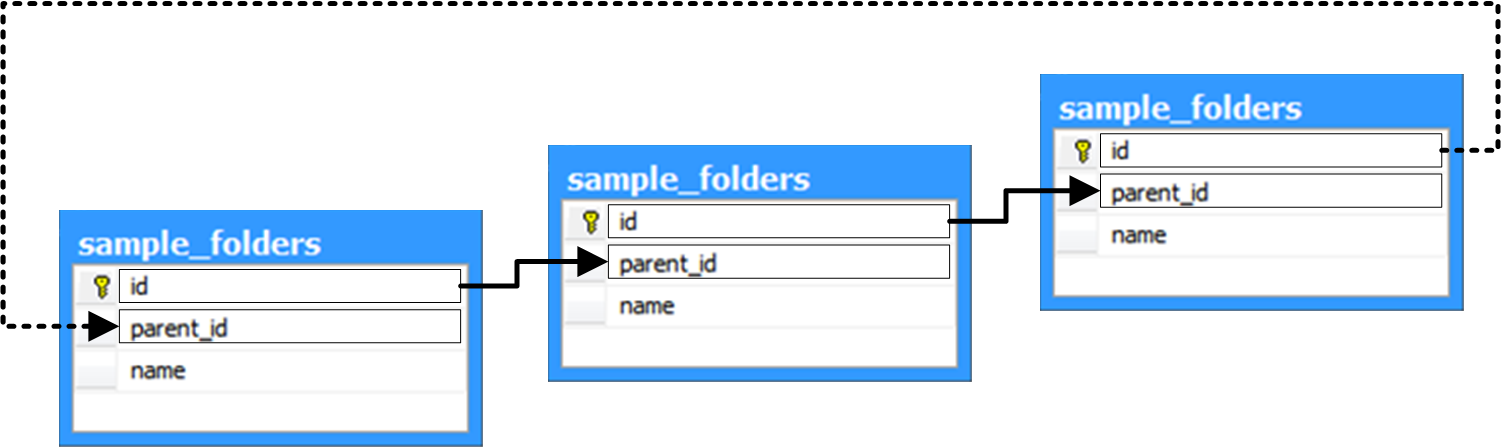
One way to prevent cycling references is to create a constraint on the folders table that tests for cycling references. The constraint may call a function that returns true (1) if the item is not valid:
CREATE FUNCTION [dbo].[Is_cyclic_folder]
(
@item_id int,
@parent_id int
)
RETURNS bit
AS
BEGIN
-- if this is a root item: OK
if @parent_id is null
return 0
-- self referencing?
if @parent_id = @item_id
return 1
declare @parent_folder_id int,
@folder_id int
-- initial parent folder
select @parent_folder_id = @parent_id
while NOT @parent_folder_id is null
begin
-- if the current parent folder is one of children folders:
-- then this item is cyclic (NOT VALID)
if @parent_folder_id = @item_id
return 1
select @folder_id = @parent_folder_id
select @parent_folder_id = parent_id
from dbo.sample_folders
where( id = @folder_id)
end
return 0
END
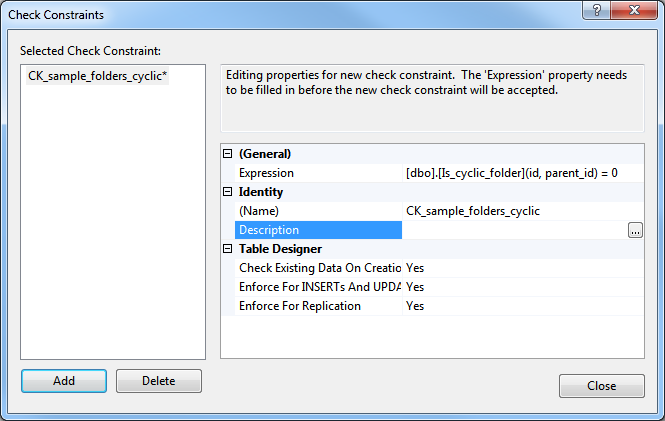
The constraint may look like this:
ALTER TABLE dbo.sample_folders ADD CONSTRAINT
CK_sample_folders_cyclic CHECK ([dbo].[Is_cyclic_folder](id, parent_id) = 0)