Introduction
The relations between some ‘real world’ objects can sometimes be in the form of ‘periodic membership’. By ‘periodic membership’, I mean the context when one object can be member of another during one or more periods of time.
Examples:
· A person who occupies a hotel room during a period of time;
· A company which is member of a portfolio during a period of time;
· … etc.
The context also assumes that we want to keep the membership history and be able to build data aggregations that take into account these periodic memberships. (For example: be able to calculate portfolio performance during a period of time that spans several ‘periodic memberships’).
A concrete example may better explain the case:
§ We have a portfolio for which we want to maintain historical performance during time;
§ At 2009/01/01, the portfolio contained : company1, company2 and company3;
§ At 2009/03/01, we changed the portfolio components and excluded company2. (Now the portfolio contains only company1 and company3);
§ At 2009/06/01, to calculate the portfolio performance for the period 2009/01/01 to 2009/06/01, we should take company2 into account for the period 2009/01/01 to 2009/03/01 (although it is no more part of the portfolio).
Knowing that database engines do not offer a ‘time-overlap’ unique indexing features, resolving this situation needs a structure that allows us to assign and manage periodic membership indexes.
Note: I am surely not the first to confront this context, but I wanted to share my experience to resolve this problem and will be glad to receive any thoughts about it.
Periodic membership multiplicity models
In my experience, I encountered two possible types of multiplicities related to periodic relationship:
§ One-to-one periodic membership: a good example for this would be a hotel room that can be occupied only by one person during the same period (i.e. period is unique per room);
§ One-to-many periodic membership: a good example for this would be a portfolio which can have more than one member for the same period (i.e. period is unique per portfolio-member).
In this article, I will explain how to handle both of these types.
Hotel room reservation, the basic structure
To demonstrate a hotel reservation periodic membership (uniqueness of room/reservation period), we can create the following table and relationships:
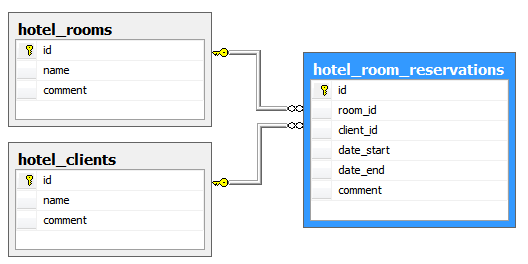
§ Hotel clients: contains client list items
§ Hotel rooms: contains room list
§ Hotel room reservations: contains client/room reservation periods
Note: the date_end field of the reservations table can be null, to allow ‘permanent’ (or endless) reservations.
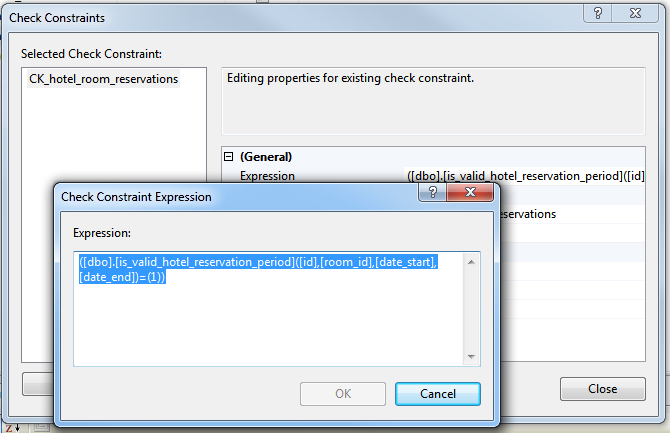
To ensure uniqueness of reservation periods, we will create a scalar function (returning a Boolean value) that can be used as Check Constraint on the hotel_room_reservations.
CREATE FUNCTION [dbo].[is_valid_hotel_reservation_period]
(
@item_id int,
@room_id int,
@date_start datetime,
@date_end datetime
)
RETURNS bit
AS
BEGIN
-- validate the provided parameters
if @date_start is null or @room_id is null
return 0
-- be sure start date < end date
if not @date_end is null
begin
if @date_start >= @date_end
return 0
end
-- is this the first reservation period for this room?
if ( select count(*)
from dbo.hotel_room_reservations
where( room_id = @room_id) ) <= 0
return 1
-- check overlapped periods
if @date_end is null -- is this a permanent (endless) reservattion?
begin
if ( select count(*)
from dbo.hotel_room_reservations
where( ( room_id = @room_id)
and( id != @item_id)
and(( date_end is null) or (date_end >= @date_start))
)) > 0
return 0
end
else
begin
if ( select count(*)
from dbo.hotel_room_reservations
where( (room_id = @room_id)
and( id != @item_id)
and( date_start <= @date_end)
and(( date_end is null) or (date_end >= @date_start))
)) > 0
return 0
end
-- return OK
return 1
END
We can now use this function as check constraint on the reservation table:
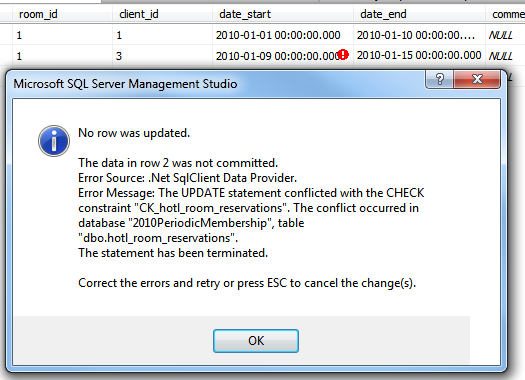
Overlapping entries in the reservation table would now display an error message like:
The Portfolio/company periodic membership case
In portfolio/company case, membership should allow multiple membership instances for different periods. That is: the same company can be member of the same portfolio several times as long as the membership periods do NOT overlap.
Our tables and relationships may look like the following:
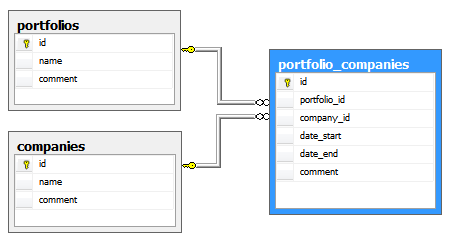
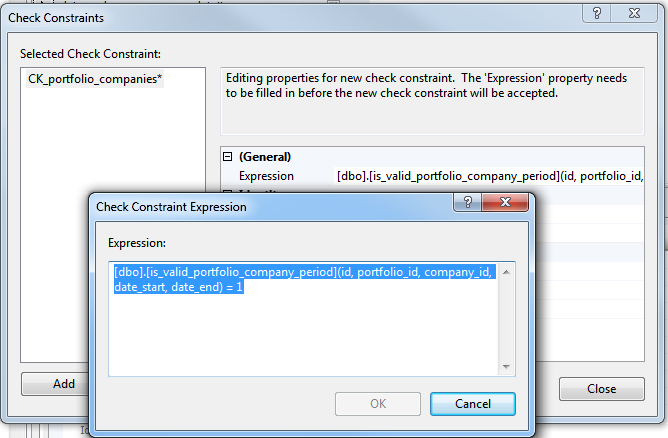
All what we need is to create a new version of the above function, and use it as a check constraint condition for the portfolio companies table:
CREATE FUNCTION [dbo].[is_valid_portfolio_company_period]
(
@item_id int,
@portfolio_id int,
@company_id int,
@date_start datetime,
@date_end datetime
)
RETURNS bit
AS
BEGIN
-- validate the provided parameters
if @company_id is null or @date_start is null or @portfolio_id is null
return 0
-- be sure start date < end date
if not @date_end is null
begin
if @date_start >= @date_end
return 0
end
-- is this the first membership period for the portfolio/company?
if ( select count(*)
from dbo.portfolio_companies
where( portfolio_id = @portfolio_id)
and( company_id = @company_id) ) <= 0
return 1
-- check overlapped periods
if @date_end is null -- is this a permanent (endless) membership?
begin
if ( select count(*)
from dbo.portfolio_companies
where( company_id = @company_id
and( portfolio_id = @portfolio_id)
and( id != @item_id)
and(( date_end is null) or (date_end >= @date_start))
)) > 0
return 0
end
else
begin
if ( select count(*)
from dbo.portfolio_companies
where( company_id = @company_id
and( portfolio_id = @portfolio_id)
and( id != @item_id)
and( date_start <= @date_end)
and(( date_end is null) or (date_end >= @date_start))
)) > 0
return 0
end
return 1
END
We can, now, use the function as a check constraint condition for the membership table:
Possible extensions
It seems that, with some more efforts, this can evolve to a generic Time-Span unique indexer.
Waiting to hear some thoughts about thisJ!