That is a second post in my series about Xamarin.
My intention is to write about various aspects of Xamarin environment, objects, architectural approaches as well as some recipes concluded by the lessons learnt through a year of intensive work in this platform.
For those who don't know about Xamarin and the Xamarin Forms offer, you may have a look at the (interesting) tale of this true modern adventure… with all the modern panoply of social experience, including unemployment and layoffs!
For a quick summary about Xamarin Forms (which is the ultimate evolution of Xamarin's offer):
Xamarin.Forms
Introduced in Xamarin 3 on May 28, 2014 and allows one to use portable controls subsets that are mapped to native controls of Android, iOS and Windows Phone.
In this post, I will try to explore important objects and mechanisms exposed in various libraries of the product. Knowledge of those is useful and may help for better understanding and usage.
Note: to explore these items, I used Visual Studio Object Browser along with Code map.
Who / What is inside?
At the root of Xamarin.Forms, two foundation objects: The BindableProperty and BindableObject.
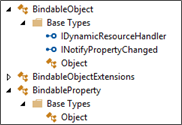
The BindableObject (abstract class… we will see some of its genealogy later) exposes:
- BindingContext which is simply an object
- BindingContextProperty: a Bindable property (bounces back to the BindingContext)
- And several events: BindingContextChanged, PropertyChanged and PropertyChanging.
The BindableProperty (a sealed class), exposes the following read-only properties (initialized, naturally, by several public constructors):
- DecalringType: System.Type
- DefaultBindingMode: BindingMode enumeration
- DefaultValue: object
- IsReadOnly: bool
- PropertyName: string
- and ReturnType: System.Type
Yes, with such an object, you are ready to sail far Overseas!
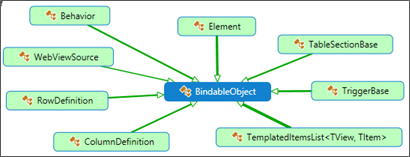
BindableObject and BindableProperty relationship
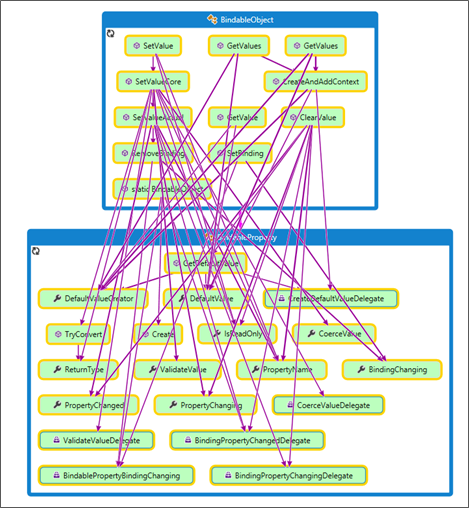
As we may expect, BindableObject makes (many) calls to BindableProperty (presumably through its BindablePropertyContext). That is a long subject that merits a specific post later. For now, let us have a look at the call mesh in the following illustration:
Exploring Xamarin Forms objects' genealogy
Who derives from BindableObject?
BindabelObject is the base class for WebViewSource à TriggerBase à Behavior à ColumnDefinition à RowDefinition à TableSectionView (what is this?J) à AND the Element!
The Element (abstract class) is the base class for à Application (!) à VisualElement (which is itself the parent of View… see below) à ImageSource (I now better understand my issues with thisJ) à GestureRecognizer à BaseMenuItem…
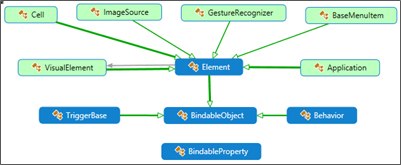
Some debatable architectural aspects seem worthy for a note:
- The Element is the base class of VisualElement.
- In the same time, it exposes a member (ParentView) which is a VisualEement!
I remember, I was threatened to be fired for having used such relationshipJ. That is to say I am not fundamentally against… but let us admit that such relationship may – at least – restrain the evolution of both the parent and derived objects.
- As you see in the figure, the ImageSource object derives from Element.
- The Image (deriving from à View, itself deriving from à VisualElement, itself deriving from à Element)… has a member 'Source' which is an Element!
I think, at this point, I would have been definitely fired if I did something like thatJ.
But why not! It only becomes just a more risky game!
The VisualElement carrefour!
VisualElement object exposes properties needed for on-screen rendering: AnchorX / Y, BackgroundColor, Bounds, Height (get) / HeightRequest, Width (get) / WidthRequest / Minimum H/W Request, Opacity, Style, Rotation… etc. It also implements Interfaces that compose the infrastructure needed for rendering the object on each platform through the platform VisualElementRenderer<T> (where T: VisualElement).
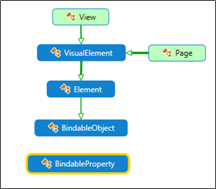
The VisualElement is the base class for two objects à Page and the View.
To avoid terminology confusions (Both View and Page are translated (rendered), in Win Phone, as a Panel (Which is a FrameworkElement)), the ViewContent (derives from View) is, approximately, what is called 'UserControl' in the Windows world. A ContentPage (derives from Page), with the same relative approximation, is what we call a Window.
To better resolve (and understand) such objects associations between Xamarin core library and a specific platform, you may use Visual Studio Objet Browser (or other assembly browser) to have a look at the renderer of the Xamarin object for the platform.
The following illustrates, for instance, the View renderer object tree for the Win Phone platform.
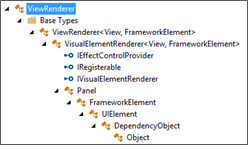
Here, it is the Image renderer on Android platform

The Page object
The page is the root object of several Types: à The ContentPage, à the NavigationPage, à the MultiPage<T> and the MatserPage.
I personally expected the Page to be a container (of Views) and that the Content property is one of the Page Object… that is not the case (deceiving ignoranceJ).
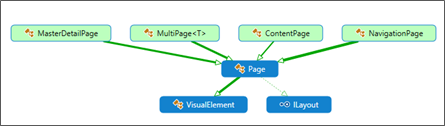
- It is the ContentPage which exposes the Content property.
- The NavigationPage exposes the (get/set) CurrentPage member property (which is a Page… so if you would like to get its 'Content', you will have to cast it to a 'ContentPage' with the risks implied in such a cast (life is dangerous!)
- With the MultiPage<T> (where T: Page) you again have a (get/set) CurrentPage property that returns a T (of Type Page)… you now know how to access something useful inside!
- The MasterDetail, as you may expect, exposes a Master and Detail (each of Type Page)
The View object
The View is the base class of à mostly all controls and layout root classes
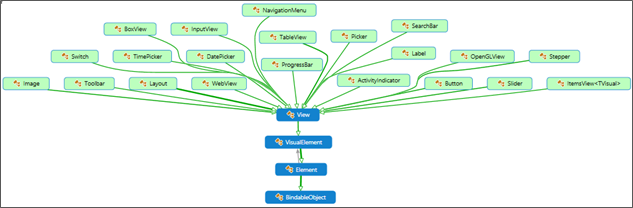
The View in everyday life
When you write <Button> in xaml (or when you write new Button(); in code), you are creating an object deriving from the View object. At runtime, your Button will be handed over to the Xamarin rendering engine to put the button on the target device's screen according to values you specified for properties of that object.
|
Note:
Not all properties are correctly transmitted or rendered on target devices (at least in the current version of Xamarin.Forms). In fact, for our Button example, some properties are not suitably tailored for all target platforms. For instance, the BorderRadius property of a Xamarin Button is not translated into anything on Win Phone.
|
The ContentView
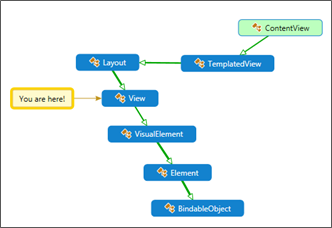
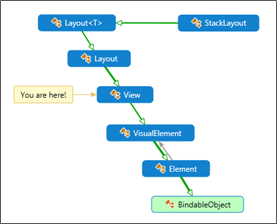
The StackLayout example
Let us take another container control deriving from the View object: the (famous) StackLayout.
StackLayout derives from ß Layout<T>. (It is a Layout<View>).
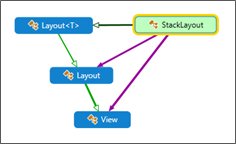
|
What Xamarin documentation says about StackLayout:
Summary:
A Xamarin.Forms.Layout`1 that positions child elements in a single line which can be oriented vertically or horizontally.
Remarks:
Because StackLayout layouts override the bounds on their child elements, application developers should not set bounds on them.
|
It exposes two properties (Both are bindable):
- Orientation (StackOrientation enumeration: Horizontal / Vertical)
- Spacing (double): the spacing between the layout elements.
Inherited properties
So, when we are using a StackLayout, we are using an IViewContainer, a Layout, a VisualElement, an Element and, ultimately, using a BindableObject.
And it is often important to remember this in order to make the most effective use of an object.
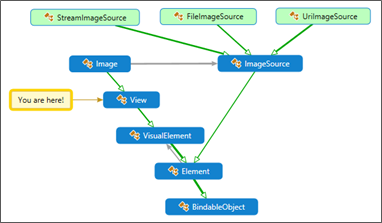
The Image example
As I mentioned above, Image is another useful example. I got confused while trying to manipulate its ImageSource property.
As the name suggests, I thought that ImageSource is a 'VisualElement'… It IS NOT J. It is an Element. It has several Load methods (from File, from Stream, from Uri…) and one (get only) CancellationTokeSource property… which is described in Xamarin documentation as: Used by inheritors to implement cancellable loads). Oddly enough, none of the derived classes delivered by Xamarin (FileImageSource, UriImageSource…) make use of this Cancellation token!
Being an Element (and thus, a BindableObject), ImageSource has few properties that you can set in a PCL project (xaml / code). That maybe one of the reasons why many questions about this object are on Xamarin developers forums!
That also makes of ImageSource a good recipe area that we will explore in a later post.
In a next post, I will explore the road it takes from your xaml (or shared code) to device screen… a long journey!