A Trie is an efficient tree structure for storing and searching hierarchically-structured information.
For more detailed information you may have a look Here, Here or Here… to mention a few.
In this article, I take 'Text' as the information to be handled.
Text can be viewed as a tree of 'character' nodes. Each set of these nodes compose a 'Word' building block. Several 'Words' building block may share a same set of character nodes.
Let us look at words like: trie, tree, try, trying. All of them share the 't' and 'r' root nodes. 'try' and 'trying' have their 't', 'r', 'y' as common nodes. This can be presented in the following simple diagram:
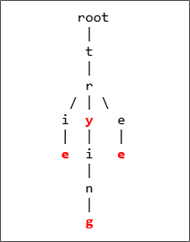
Or, in a more graphical presentation, like the figure below (green nodes represent end of words):
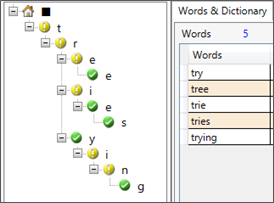
In the case of Text, the efficiency of a Trie is that any word of a given text will start with one of the known alphabetical characters of the language used. Which represents a relatively limited number of nodes.
To enhance our tree structure, we may choose to compose our root nodes with only characters used in the manipulated text (i.e. dynamically compose our root character dictionary).
Trie classes
The following class diagram presents the main Trie model used in the application code:
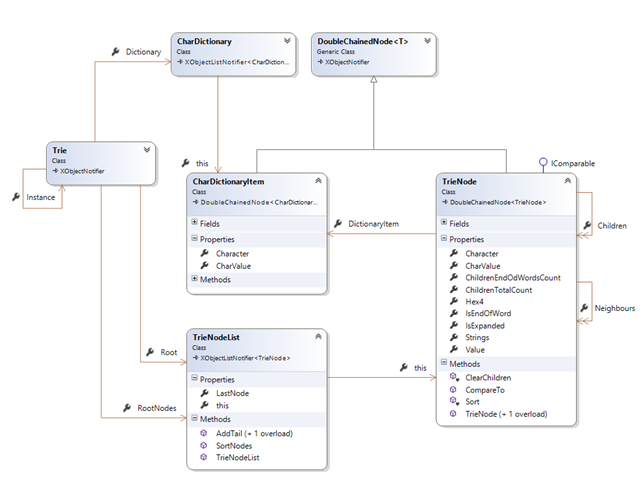
- CharDictionaryItem: stores one character information (its 'char' value… from which we can get its int value)
- CharDictionary: the collection or CharDictionaryItem used as the root dictionary for all nodes
- TrieNode: a trie node item. It refers to one of the above dictionary's nodes. Contains a IsEndOfWord flag that tells whether the node is the end of a word building bloc. And provides information related to its status and position in the tree (Children, Neighbors, IsExpanded…). Through its tree position and flags, a TrieNode object can provide us with useful information such as 'words' (Strings) found at its specific position.
- TrieNodeList: a collection of TrieNode items.
- Trie: is the central object. It contains a CharDictionary and a TrieNodeList. This class is implemented as a singleton in the current sample application.
Collection indexers
Collections (CharDictionary, TrieNodeList) expose a useful indexer that retrieves an item by its character. Those indexers will be used through the code for retrieving items.
TrieNodeList indexer:
public TrieNode this[char c]
{
get { return this.FirstOrDefault(item => item.Character == c); }
}
CharDictionary indexer:
public CharDictionaryItem this[char c]
{
get { return this.FirstOrDefault( item => item.Character == c); }
}
The sample scenario
The sample application proposes the following usage scenario:
- User selects a text file
- Parse the file's contents: get its words blocks
- Compose the root character dictionary
- Build the words tree
- Display the presentation tree + additional search functionalities
Parsing text – sample code
Parse text words (having a minimum length: (= 3 chars in the sample app))
int ParseStringTask(string str, int minWordLength)
{
// split text words
string[] words = str.Split(new string[]
{
" ", "\r\n", "(", ")", ",", ".", "'", "\"",
":", "/", "'", "'", "«", "»", "-", "+", "=",
"*", "[", "]", "{", "}", ";", "&", "<",
">", "|", "\\", "`", "^", "…", "\t"
}, StringSplitOptions.RemoveEmptyEntries);
string word;
foreach (string w in words)
{
word = w.Trim();
if (word.Length >= minWordLength)
{
this.AddString(word); // add this word to the tree
}
}
return this._nodes.Count;
}
AddString method: creates the new dictionary items / adds the tree nodes of a string block (word)
public void AddString(string str)
{
char c = str[0];
CharDictionaryItem dicoItem;
TrieNode firstNode = _nodes[c],
node;
int ndx,
len = str.Length;
if(firstNode == null)
{
// find the dictionary item. add it if none found
dicoItem = GetDictionaryItem(c);
firstNode = _nodes.AddTail(dicoItem);
}
for(ndx = 1; ndx < len; ndx++)
{
c = str[ndx];
node = firstNode.Children[c];
// find the dictionary item. add it if none found
dicoItem = GetDictionaryItem(c);
if(node == null)
{
node = firstNode.Children.AddTail(dicoItem);
}
if(ndx >= len -1)
{
// set the End of word flag
node.IsEndOfWord = true;
}
firstNode = node;
}
}
Reading back the trie words
How to find back our parsed words through the trie?
Here is a sample code to find words located at a given node:
TrieNode.Strings property:
public List<string> Strings
{
get
{
List<string> list = new List<string>();
var childWords = from c in _children where(c._isEndofWord == true) select c;
List<string> neigbors = Next == null ? null : Next.Strings;
string strThis = this.Character.ToString();
// add words found in immediate neighbors
if(childWords != null)
{
string str = strThis;
foreach(TrieNode n in childWords)
{
str += n.Character.ToString();
if(n.IsEndOfWord)
list.Add( str);
}
}
// add words that may be found in child nodes
foreach(TrieNode childNode in _children)
{
foreach(string str in childNode.Strings)
list.Add(strThis + str);
}
return list;
}
}
User interface (WPF)
Trie nodes can easily be presented in a TreeView. According to the trie node flag, its corresponding tree view node should be able to indicate this (through different image in our example, using a Converter)
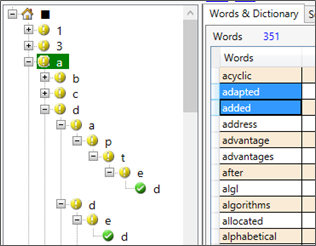
The Tree view item template may be:
<TreeView.ItemTemplate>
<HierarchicalDataTemplate ItemsSource="{Binding Children}">
<StackPanel Orientation="Horizontal" Margin="0" >
<Image Width="14"
Source="{Binding Converter={StaticResource nodeImageConverter}}"
Margin="0,0" />
<TextBlock Text="{Binding Character}" Padding="4,0"
Margin="4,0" VerticalAlignment="Center" />
</StackPanel>
</HierarchicalDataTemplate>
</TreeView.ItemTemplate>
Searching trie words
Fins words starting with a given string (Trie class)
public List<string> StartsWith(string str)
{
List<String> list = new List<string>();
char c = str[0];
TrieNode node0 = this._nodes[c];
if(node0 == null)
return list;
List<string> strings = node0.Strings;
foreach(string s in strings)
{
if(s.StartsWith(str, true, CultureInfo.CurrentCulture))
list.Add(s);
}
return list;
}
Fins words containing a given string (Trie class)
public List<string> Containing(string str)
{
List<String> list = new List<string>();
if(string.IsNullOrEmpty(str))
return list;
foreach(TrieNode node in this._nodes)
{
var strings = from sx in node.Strings where( sx.Contains(str)) select sx;
foreach(string s in strings)
{
list.Add(s);
}
}
return list;
}
Sample app screenshots
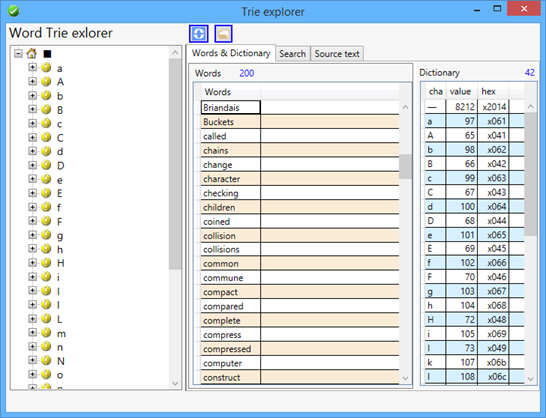
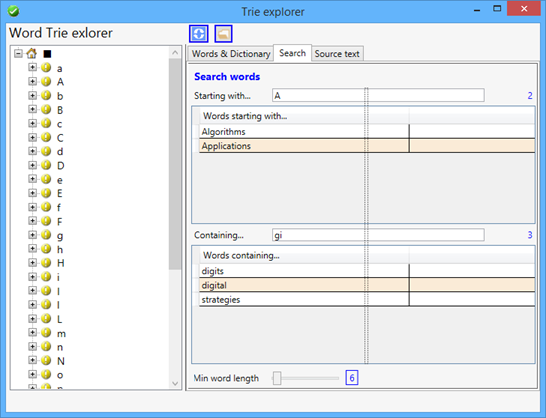
The sample code
You may download the source code Here.
Have fun optimizing the code and adding new features!